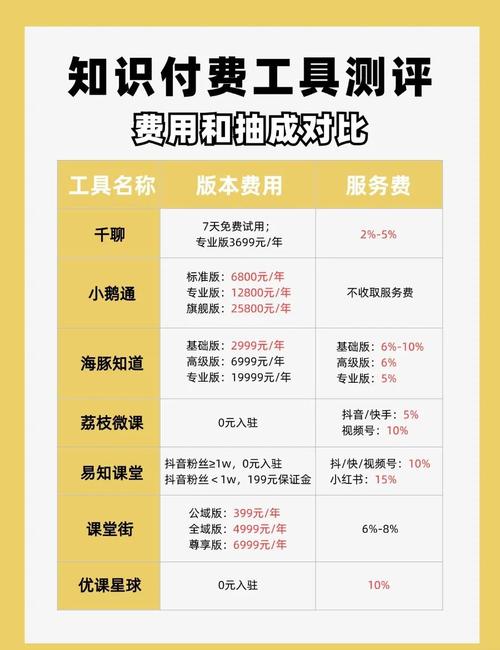
1. 学习网页设计与开发:通过查看优秀网站的源代码,新手开发者可以学习到HTML(超文本标记语言)、CSS(层叠样式表)和JavaScript等语言的实际应用,了解页面布局、样式设计和交互功能的实现方式,加速自身技能提升。
2. 分析竞争对手:对于企业或网站运营者而言,提取竞争对手网站的源代码可以分析其页面结构、技术选型和组织方式,从而发现自身优势与不足,制定更具竞争力的策略。
3. 解决网页显示问题:当网页在浏览器中出现显示异常时,查看源代码有助于定位问题所在,如HTML标签错误、CSS样式冲突或JavaScript脚本错误等,进而进行针对性修复。
二、提取网站源代码的常见方法
(一)使用浏览器自带工具
1. Chrome浏览器:在Chrome浏览器中,只需右键点击网页任意位置,选择“查看网页源代码”,即可打开一个新窗口显示该网页的HTML代码。若要查看包含CSS和JavaScript等动态效果相关代码,可按F12键打开开发者工具,在“Elements”标签下查看实时渲染的页面结构及样式,在“Sources”标签下查看JavaScript文件。
2. Firefox浏览器:同样通过右键菜单选择“查看页面源代码”可获取HTML代码。按下Ctrl + Shift + I组合键打开开发者工具,其界面布局与Chrome类似,“Inspector”标签用于查看页面元素和样式,“Debugger”标签用于调试JavaScript。
3. Safari浏览器:默认情况下,Safari浏览器需在“偏好设置” - “高级”中勾选“在菜单栏中显示‘开发’菜单”。之后,通过右键点击网页选择“查看源代码”获取HTML,使用“开发”菜单中的“显示Web检查器”查看更详细的代码及调试信息。
(二)借助第三方工具
1. Wget:这是一款适用于Linux和Windows(通过安装Git Bash等工具)的命令行下载工具。例如,在命令行输入“wget [网站URL]”,即可将网页下载到本地,包括其源代码。可通过添加参数如“-p”来下载网页所需的所有资源,如图片、CSS和JavaScript文件,方便离线查看和分析。
2. HTTrack:这是一个功能强大的离线浏览器工具,它可以将整个网站下载到本地,包括所有页面、图片、样式表和脚本等。用户只需输入网站地址,设置好下载路径和相关选项(如是否递归下载子页面、是否过滤特定文件类型等),HTTrack就能自动完成下载,生成与原网站相似的本地副本,便于深入研究源代码。
三、提取网站源代码的注意事项
1. 版权问题:虽然提取网站源代码用于个人学习和研究通常是被允许的,但未经授权将提取的代码用于商业用途或直接抄袭复制,可能会侵犯网站所有者的版权,引发法律纠纷。在使用提取的代码时,务必确保遵循相关法律法规和道德准则。
2. 动态网站限制:许多现代网站采用了动态加载技术,如AJAX(异步JavaScript和XML),浏览器直接查看的源代码可能只是初始加载的静态部分,动态加载的无法直接在源代码中看到。此时,需要使用开发者工具中的“Network”标签,通过监测网络请求来获取动态加载的数据和相关代码。
3. 反爬虫机制:部分网站为了保护自身数据和资源,设置了反爬虫机制。过度频繁地提取源代码或使用自动化工具可能会触发这些机制,导致IP被封禁。在提取代码时,应尽量模拟正常用户行为,避免对网站服务器造成过大压力。
提取网站源代码是一把双刃剑,合理运用可以为我们的学习、工作带来诸多便利,但不当使用则可能引发一系列问题。掌握正确的提取方法和遵循相关规则,能让我们在探索网络世界的道路上走得更加稳健,充分挖掘互联网背后的技术宝藏。